As part of my adventures in natural language processing and learning Python, I wanted to try to learn how to make word clouds. We see these things all the time in powerpoint presentations.
They look fairly cool and the technology used to create them seems fairly straightforward. The computer counts the number of times a word appears in some text. Words that appear more frequently are bigger (ignoring common words like “the,” “of,” “a” and such) and words that appear sometimes but not as frequently are still shown, but take up less space.
This was a bit before the 2020 election and I wanted to see if different news sources were covering different topics and I wanted to be able to visualize these differences easily.
I wrote some code (some repurposed from https://www.datacamp.com/community/tutorials/wordcloud-python ) to scrape the RSS feeds of various news sources and generate word clouds. These were the clouds I got from CNN and BBC.
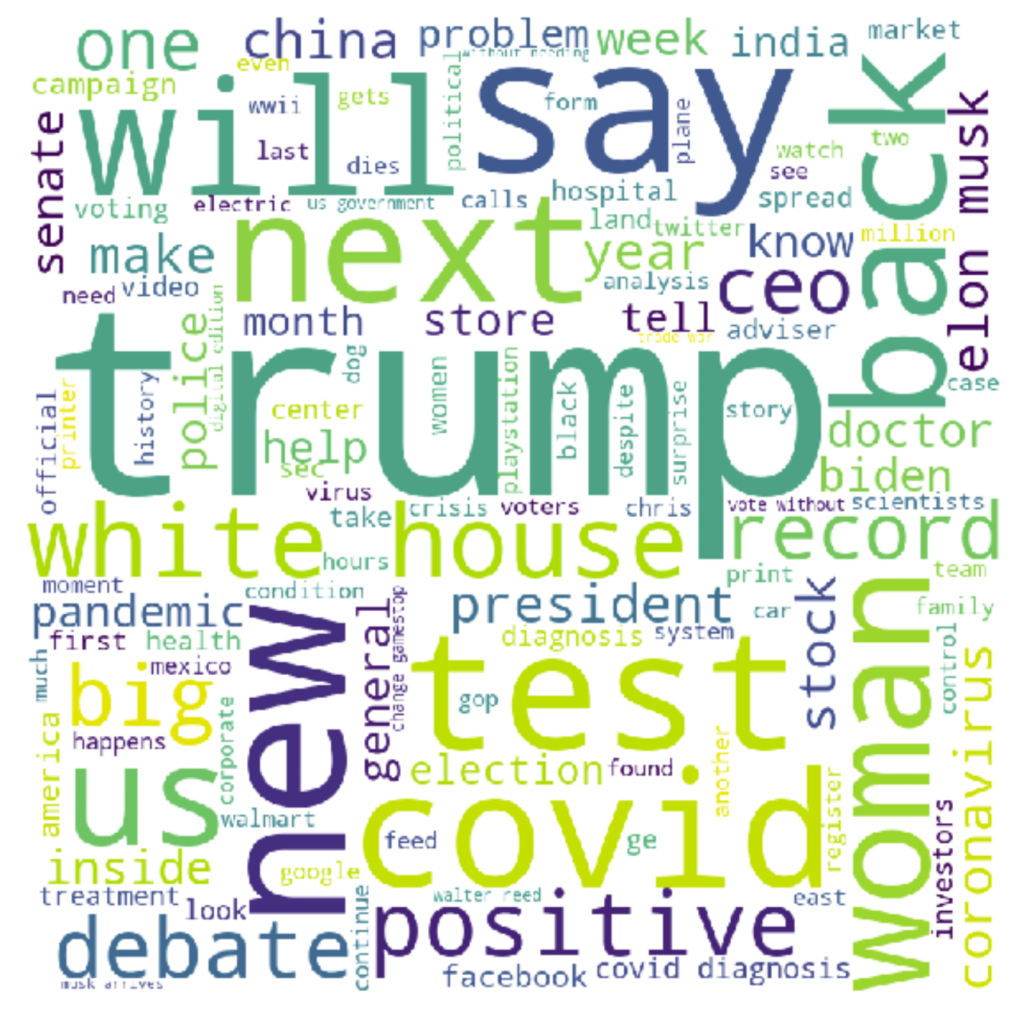

And this is the code I used to generate it. It’s currently set up for the CNN URLs, but you can put in what RSS feed URLs in and it should work (you will need to appropriately indent it to get it working, the indents don’t paste properly, unfortunately).
#import library
import requests
from bs4 import BeautifulSoup
#import pandas to create dataframe and CSV
import pandas as pd
import time
from wordcloud import WordCloud, STOPWORDS
import matplotlib.pyplot as plt
#enter URL
cnnurls = ["http://rss.cnn.com/rss/cnn_topstories.rss",
"http://rss.cnn.com/rss/cnn_world.rss",
"http://rss.cnn.com/rss/cnn_us.rss",
"http://rss.cnn.com/rss/money_latest.rss",
"http://rss.cnn.com/rss/cnn_allpolitics.rss",
"http://rss.cnn.com/rss/cnn_tech.rss",
# "http://rss.cnn.com/rss/cnn_health.rss",
# "http://rss.cnn.com/rss/cnn_showbiz.rss",
# "http://rss.cnn.com/rss/cnn_travel.rss",
"http://rss.cnn.com/rss/money_news_companies.rss",
"http://rss.cnn.com/rss/money_news_international.rss",
"http://rss.cnn.com/rss/money_news_economy.rss"
]
bbcurls = ["http://feeds.bbci.co.uk/news/rss.xml",
"http://feeds.bbci.co.uk/news/world/rss.xml",
"http://feeds.bbci.co.uk/news/uk/rss.xml",
"http://feeds.bbci.co.uk/news/business/rss.xml",
"http://feeds.bbci.co.uk/news/politics/rss.xml",
# "http://feeds.bbci.co.uk/news/health/rss.xml",
"http://feeds.bbci.co.uk/news/education/rss.xml",
"http://feeds.bbci.co.uk/news/technology/rss.xml",
"http://feeds.bbci.co.uk/news/entertainment_and_arts/rss.xml"
]
news_items = []
for url in cnnurls:
resp = requests.get(url)
soup = BeautifulSoup(resp.content, features="xml")
items = soup.findAll('item')
#print(len(items))
#scarring HTML tags such as Title, Description, Links and Publication date
for item in items:
news_item = {}
news_item['title'] = item.title.text
news_item['description'] = item.description.text
# news_item['link'] = item.link.text
# news_item['pubDate'] = item.pubDate.text
news_items.append(news_item)
time.sleep(1)
df = pd.DataFrame(news_items,columns=['title','description'])
df.to_csv('CNNdata1.csv',index=False, encoding = 'utf-8')
df = pd.read_csv('CNNdata1.csv',encoding = 'utf-8')
comment_words = ''
stopwords = set(STOPWORDS)
# iterate through the csv file
for val in df.title:
# typecaste each val to string
val = str(val)
# split the value
tokens = val.split()
# Converts each token into lowercase
for i in range(len(tokens)):
tokens[i] = tokens[i].lower()
comment_words += " ".join(tokens)+" "
wordcloud = WordCloud(width = 800, height = 800,
background_color ='white',
stopwords = stopwords,
min_font_size = 10).generate(comment_words)
# plot the WordCloud image
plt.figure(figsize = (8, 8), facecolor = None)
plt.imshow(wordcloud)
plt.axis("off")
plt.tight_layout(pad = 0)
plt.show()