In the previous posts, I covered how to scrape some data (like a stock price) from a website. To get a workable dataset, we can write some code to continually loop, and collect that same data at a fixed interval.
The code below does this. A few points. (1) Python uses indentation as part of the syntax. After starting a loop (the while 1==1: statement below) or a conditional (the if XXX==YYY statement below), everything you want looping or conditionally done has to be indented. (2) the while 1==1 line simply says keep doing this … forever. Since 1 will always be equal to 1. and (3) the if statement below checks if the current minute is divisible by 5 and runs the scraping code if it is. You can change the interval by changing 5 to another number, or using the now.second or now.hour numbers.
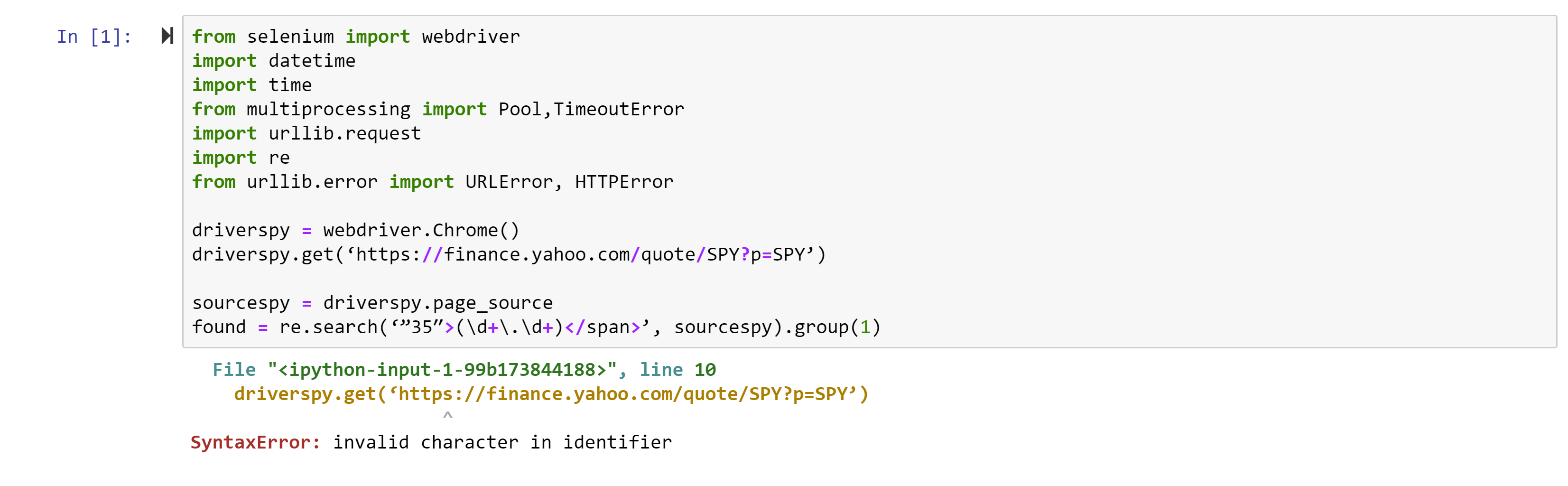
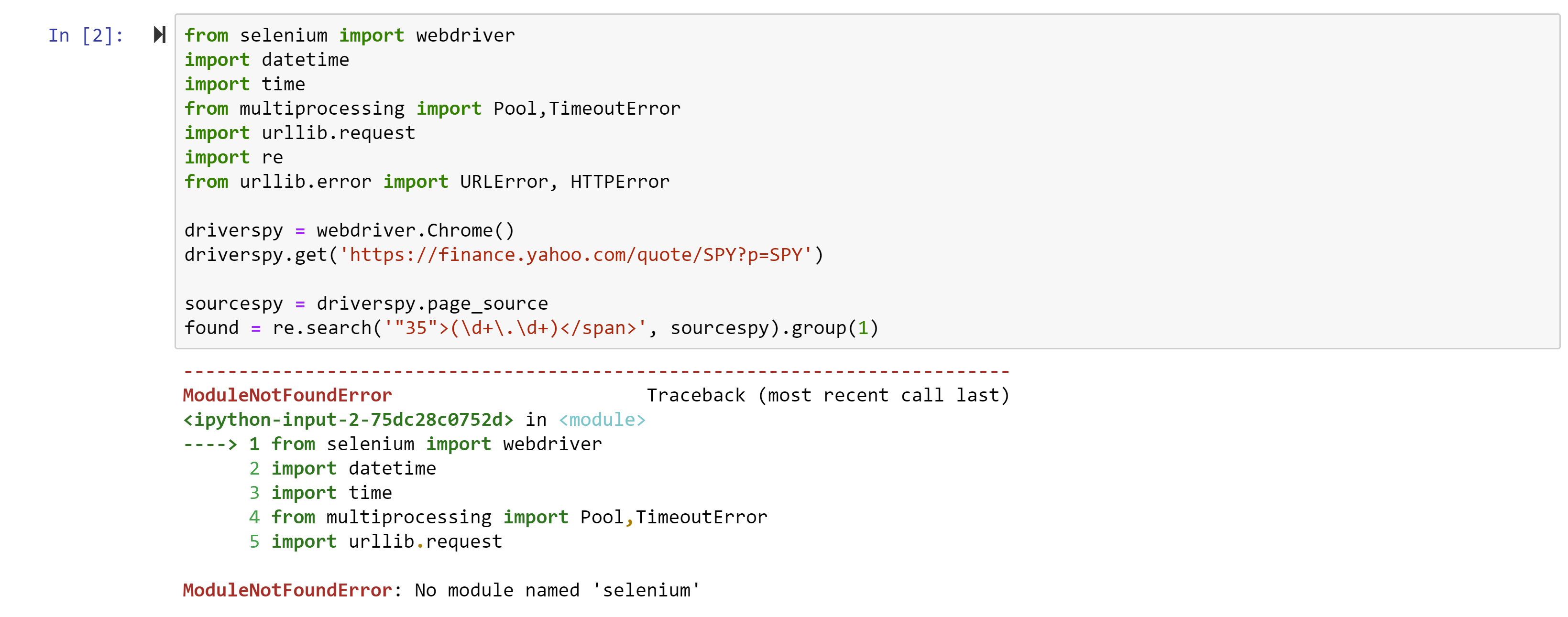
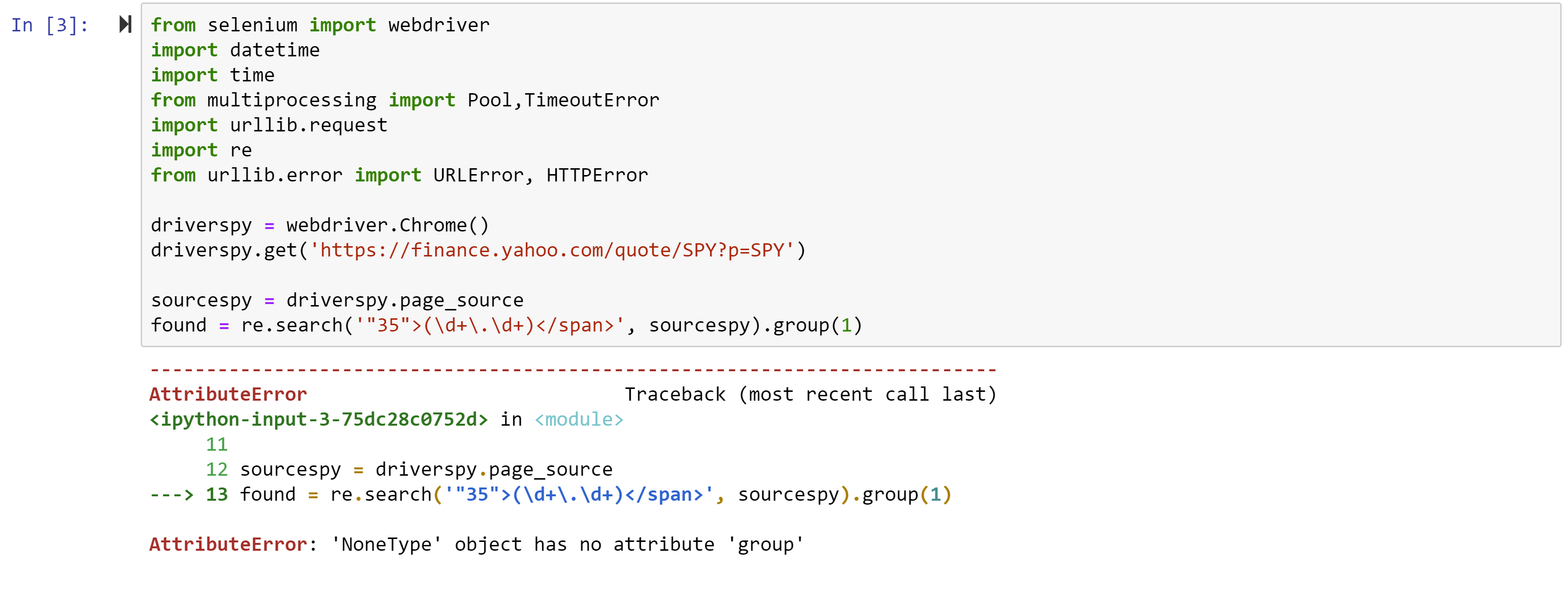
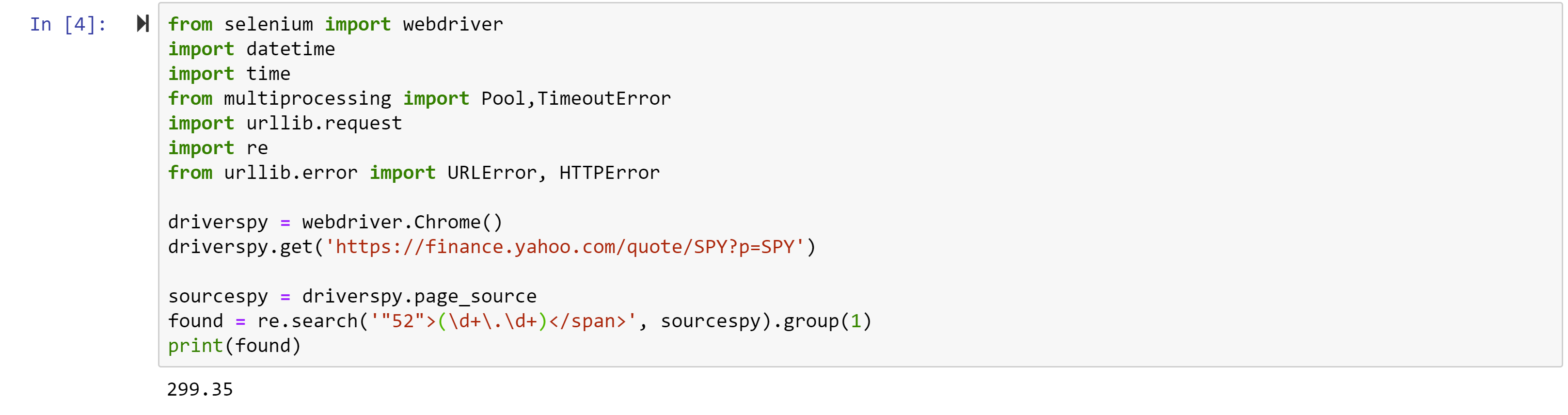
from selenium import webdriver
import datetime
import time
from multiprocessing import Pool,TimeoutError
import urllib.request
import re
from urllib.error import URLError, HTTPErrorwhile 1==1:
now = datetime.datetime.now()
if now.minute/5 == int(now.minute/5):
driverspy = webdriver.Chrome()
driverspy.get(‘https://finance.yahoo.com/quote/SPY?p=SPY’)
sourcespy = driverspy.page_source
now = datetime.datetime.now()
found = re.search(‘”52″>(\d+\.\d+)</span>’, sourcespy).group(1)
print(“Time:”+str(now.hour)+”:”+str(now.minute)+”:”+str(now.second)+” Price:”+str(found))
time.sleep(75)
driverspy.quit()
While the code runs, you’ll get output that looks like the following. You can then either copy paste this to a CSV file or use Python code to export it in order to start building a dataset.
Time:12:15:20 Price:302.10 Time:12:20:8 Price:302.08 Time:12:25:19 Price:302.05 Time:12:30:20 Price:302.07 Time:12:35:9 Price:302.17 Time:12:40:9 Price:302.09 Time:12:45:28 Price:302.22 Time:12:50:28 Price:302.24 Time:12:55:16 Price:302.26 Time:13:0:8 Price:302.18 Time:13:5:9 Price:302.01 Time:13:10:8 Price:301.96 Time:13:15:28 Price:302.01 Time:13:20:29 Price:302.04 Time:13:25:8 Price:301.96 Time:13:30:20 Price:301.96 Time:13:35:19 Price:302.10 Time:13:40:28 Price:302.27 Time:13:45:20 Price:302.24 Time:13:50:8 Price:302.21 Time:13:55:8 Price:302.19 Time:14:0:8 Price:302.16